

In this series, I am going to discuss and demonstrate the importance of Automation. I will leverage the following technologies:
DV2.0 Automation solution will be Vaultspeed
Database solution will be Snowflake
Orchestration solution will be Airflow
Vaultspeed is an online tool that is a web based fully SaaS (Software as a Service) Data Vault 2.0 Automation solution. I have done a few Data Vault implementations now with the solution and was able to learn and leverage and adopt the solution quite quickly. In this 10-part series I will share my experience with the technology and demonstrate how you can automate your Data Vault implementation for your organization.
Let’s get started…
Why Automation?
First off, why would you want to automate your Data Warehouse Implementation?
Believe it or not, I get this question quite often. Many organizations that have been supporting and building Data Warehouses for years and are being done manually. Leveraging teams of developers who write data integration mappings and pipelines to source, transform and load data into Data Warehouse structures, taking up valuable time and resources. “It's just the way we do it” they say. They are right, for many years this is how Data Warehouse projects executed. But, as companies embrace digital transformation within their enterprise, there are several obstacles and challenges organizations are struggling to overcome. Managing new data formats, speeding up data analysis, and manual (and slow) data movement have been found to block the benefits and often cost millions to fix or work around.
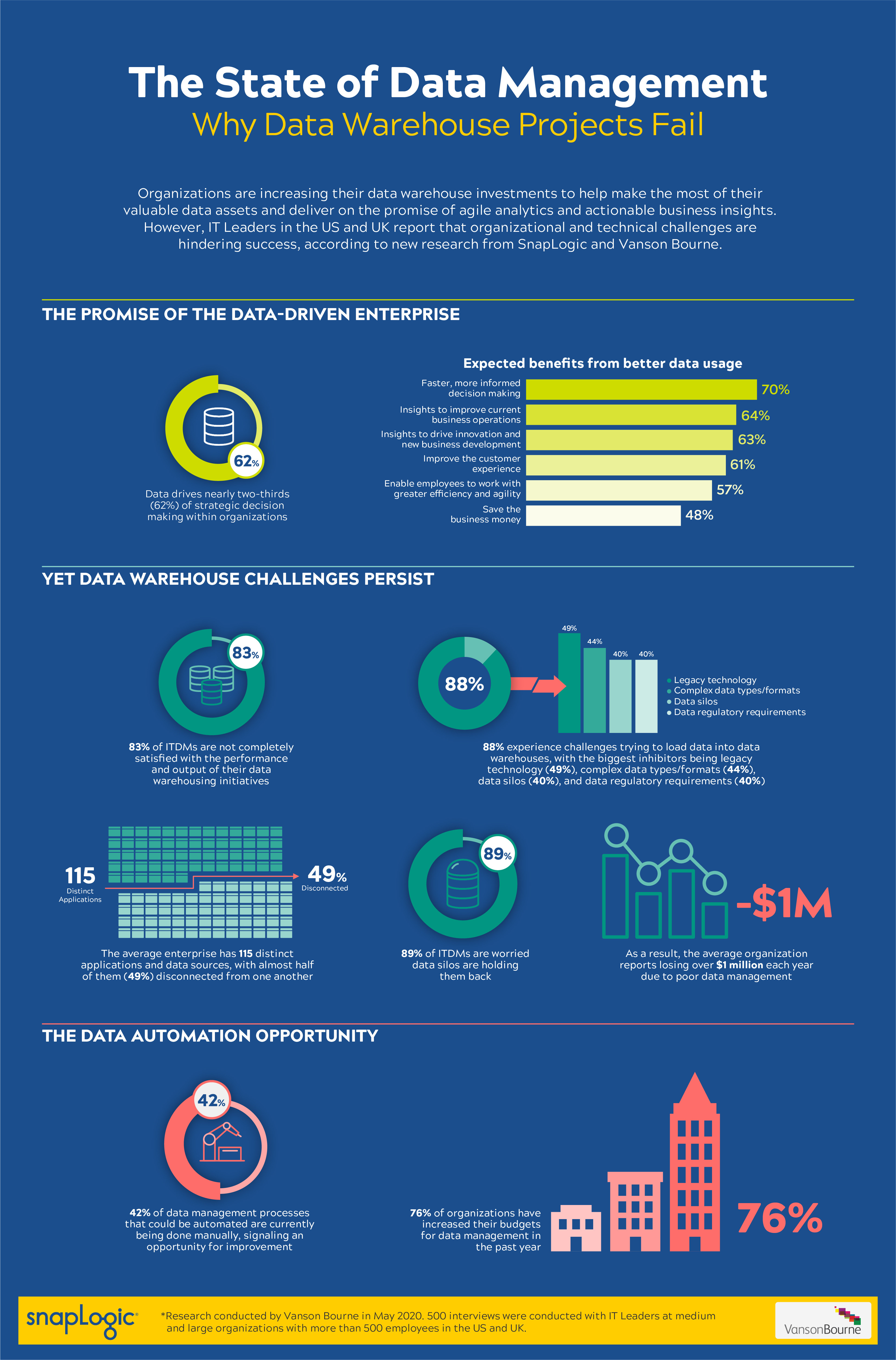
conducted by Vanson Bourne, who surveyed 500 IT Decision Makers across the US and UK, shows that businesses are still struggling to manage their data challenges. With 93% believing that improvements are needed in how data is collected, managed, stored, and analyzed. 88% saying they are experiencing challenges trying to load data into their data warehouse. Research also shows organizations are currently using an average of four different solutions to integrate and move data into and out of their data warehouse implementations. This information shows how using many different data integration tools introduces risk, duplication, and quality issues, while also increasing the labor needed to get an expected ROI.
Automating these manually developed data pipeline processes, such as the integration of disparate data sources into your data warehouse, shortens your time to market and reduces your financial investment, also reducing the time it takes for your analyst community to see value. In that same report it is believed that 42% of the processes within your data management ecosystem being done manually today could be automated.
What does Data Vault 2.0 have to do with automation?

Now that we identified the benefits and importance of introducing automation into your data management strategy. There are still some key ingredients that must be in place for automation to be successful. From my perspective a few key characteristics need to be in place. Those are Volume, Stability and Standardization. What do I mean by these? Let’s take for example a fast-food restaurant (Yes, I couldn’t go a post without bringing in a food analogy) A fast-food restaurant needs to be able to cater to a large Volume of customers in a short amount of time. But at the same time, they need have a consistency to their product to retain those customers and if they are a franchise, they need that consistency to hold true regardless of personnel and that requires Standardization in how things are done. But lastly and not to be forgotten is that all these standard processes need to be backed up by infrastructure and processes that are stable to support the volume of customers and those standardized processes. All these working together empower these businesses to be successful in meeting their objectives. If they are not, you may get asked to pull over to the side as they are still waiting for the French Fries to get made.
This is where Data Vault 2.0 comes into play and why many organizations are now
looking to transition from their traditional (Bus Architecture) Data Management approach to a Data Vault 2.0 approach as part of their Digital Transformation initiatives. As organizations are make that decision to move from legacy on Prem data systems and over to cloud based and modern technology. They are using this opportunity to also change and enhance their data management strategy.
Let’s break Data Vault 2.0 down in how it supports that ability to provide automation and how it supports my three characteristics.
Volume is not going to come from Data Vault 2.0. But Volume is coming from within your organization. There is no shortage of Volume these days with the number of data sources that businesses have at their disposal (Internally and externally). Added to the disparate number of sources, is the amount of data being created and it is growing exponentially. The days of batch pulling data from a few sources once a day for your Data Warehouse is behind us. Though some of those legacy systems exist, new modern sources of data are pushing organizations to leverage Real-Time Streaming data. Data Vault 2.0 Methodology, Architecture and Model provide direction on how to handle this modern volume of data. Here is an example for Snowflake from the Data Vault Alliance (https://datavaultalliance.com/news/building-a-real-time-data-vault-in-snowflake/)
Standardization from my perspective is probably the single most identifiable aspect of Data Vault 2.0. I like to say it is so simple that it is hard. What do I mean by that? Data Vault 2.0 has a very small number of core objects that regardless of your Business Vertical, Organization Size and Budget. Data Vault 2.0 still fits. You are working primarily with Three core object types (Hubs, Links & Satellites) and a Couple of query assist objects (PITs & Bridges). To compliment those objects are critical standards that are to be followed to make each of them meet their objective roles. Now what makes it hard is that all the members of your organization must follow all these standards exactly with no deviation. Any deviation and you open the door for things to go in a bad direction.
Stability solutions are also found throughout the Data Vault 2.0 Solution. It is found in all three pillars (Methodology, Architecture & the Model). Data Vault 2.0 methodology identifies techniques on how to make your data fully auditable back to the source. How you should develop your pipelines to proactively look for and handle bad data so that your pipelines run. These are just a couple examples or areas Data Vault 2.0 provides solutions for stability. What is great about Data Vault 2.0 is that it is Technology, Vertical and Data Type agnostic. If you follow the documented solutions, you should have a very stable Data Warehouse that will scale and perform as your environment evolves.
However, let me just reiterate how difficult and time consuming it will be if you attempt to execute on Data Vault 2.0 leveraging Manual Development techniques. I can speak from personal experience on the difficulties it is to get many people all developing, modeling, and executing in the exact same way across all your subject areas and use cases. This emphasizes my earlier point “88% saying they are experiencing challenges trying to load data into their data warehouse”. Data Vault 2.0 however provide the perfect recipe for Automation and the solution improving the industry experience in trying to improve the challenges with loading your Data Warehouse.
For more information on Data Vault 2.0 be sure to check out the Data Vault Alliance site and don’t forget to join and follow the North America Data Vault User Group
Comments